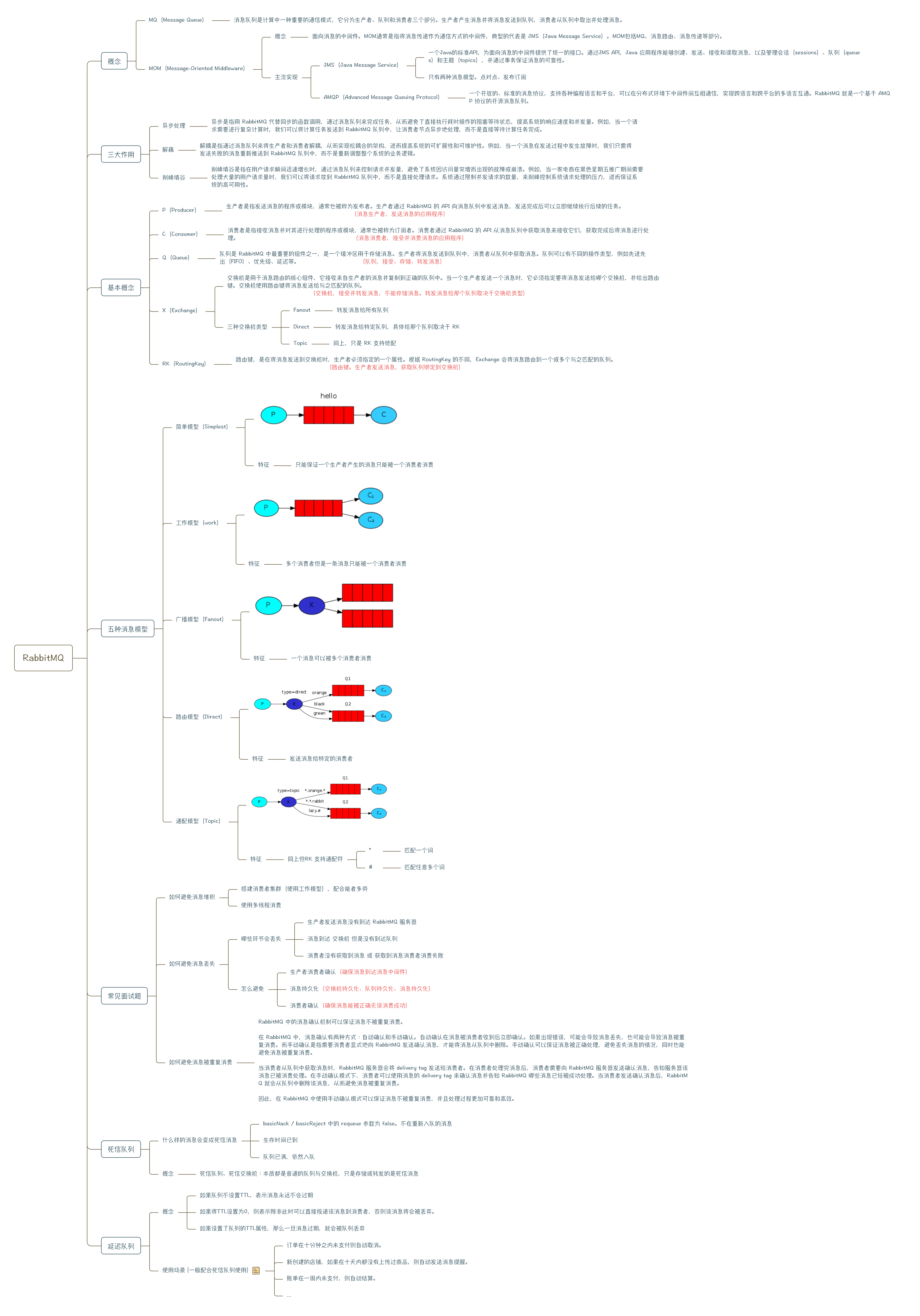
RabbitMQ 学习
这是一个基于 RabbitMQ 的学习项目,主要目的是掌握 RabbitMQ 的基本概念和使用方法,方便之后实际项目中进行消息队列的应用。
项目工程模块介绍
| 工程名称 |
作用 |
介绍 |
| producer |
生产者 |
生产者只需要添加 amqp 启动器即可(只发消息即可) |
| consumer |
消费者 |
消费者不仅需要添加 amqp 还需要添加 web 启动器(需要实时监听队列) |
Docker 安装 RabbitMQ
下载
1
| docker pull rabbitmq:management
|
启动
1
| docker run -d -p 5672:5672 -p 15672:15672 -p 25672:25672 --name rabbitmq rabbitmq:management
|
设置开机自启
1
| docker update rabbitmq --restart=always
|
网页端地址
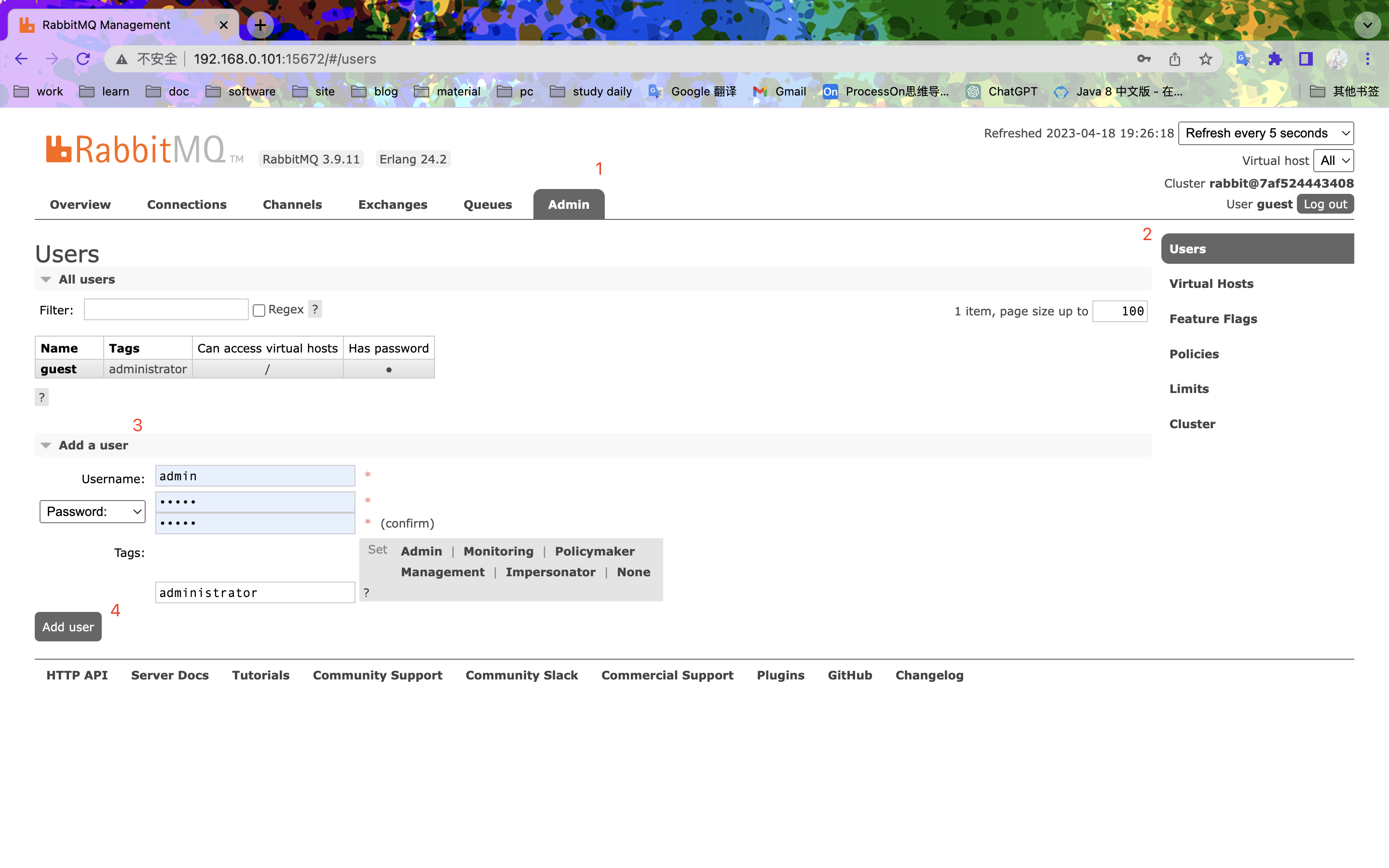
控制台
新增用户
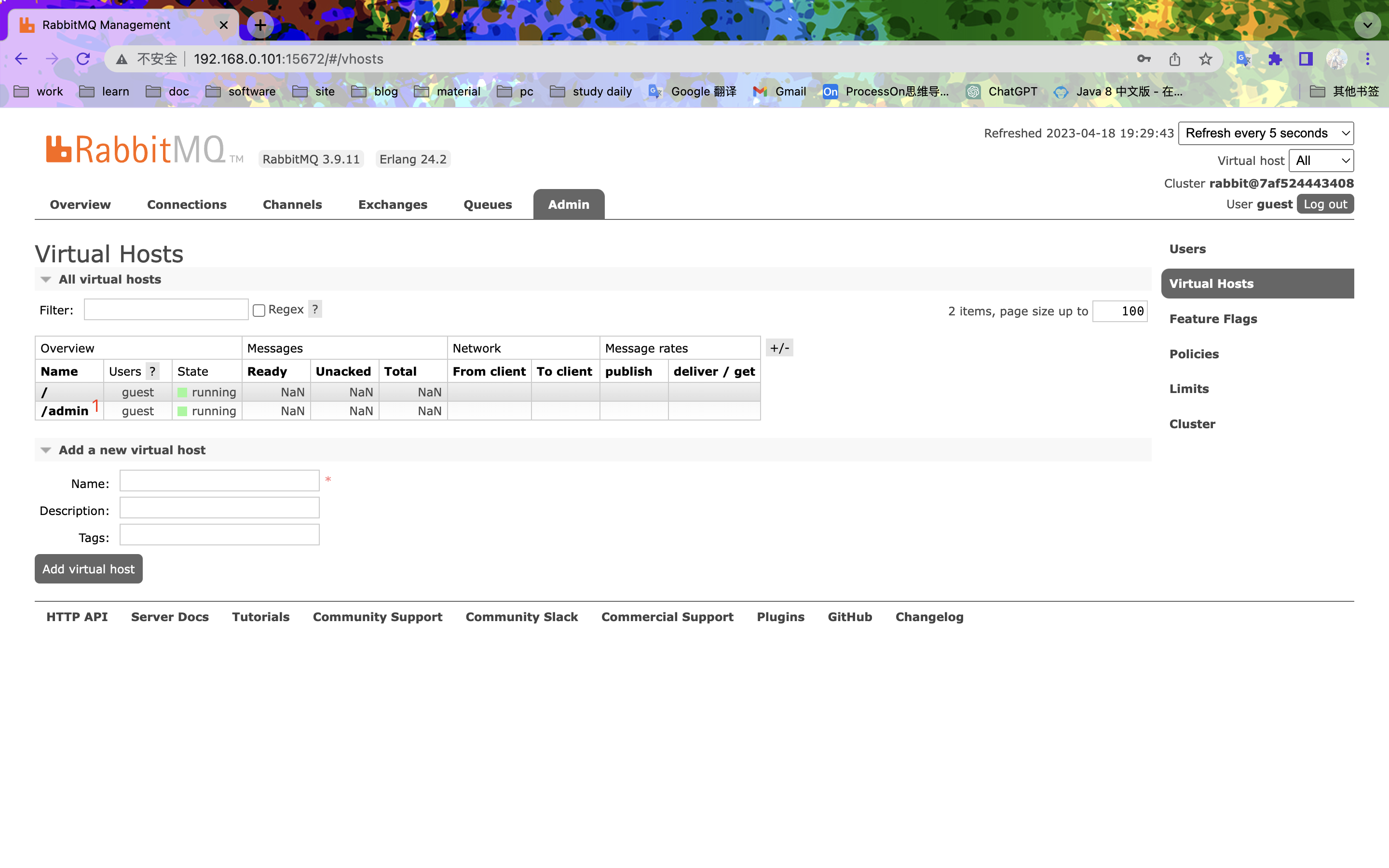
新增虚拟主机
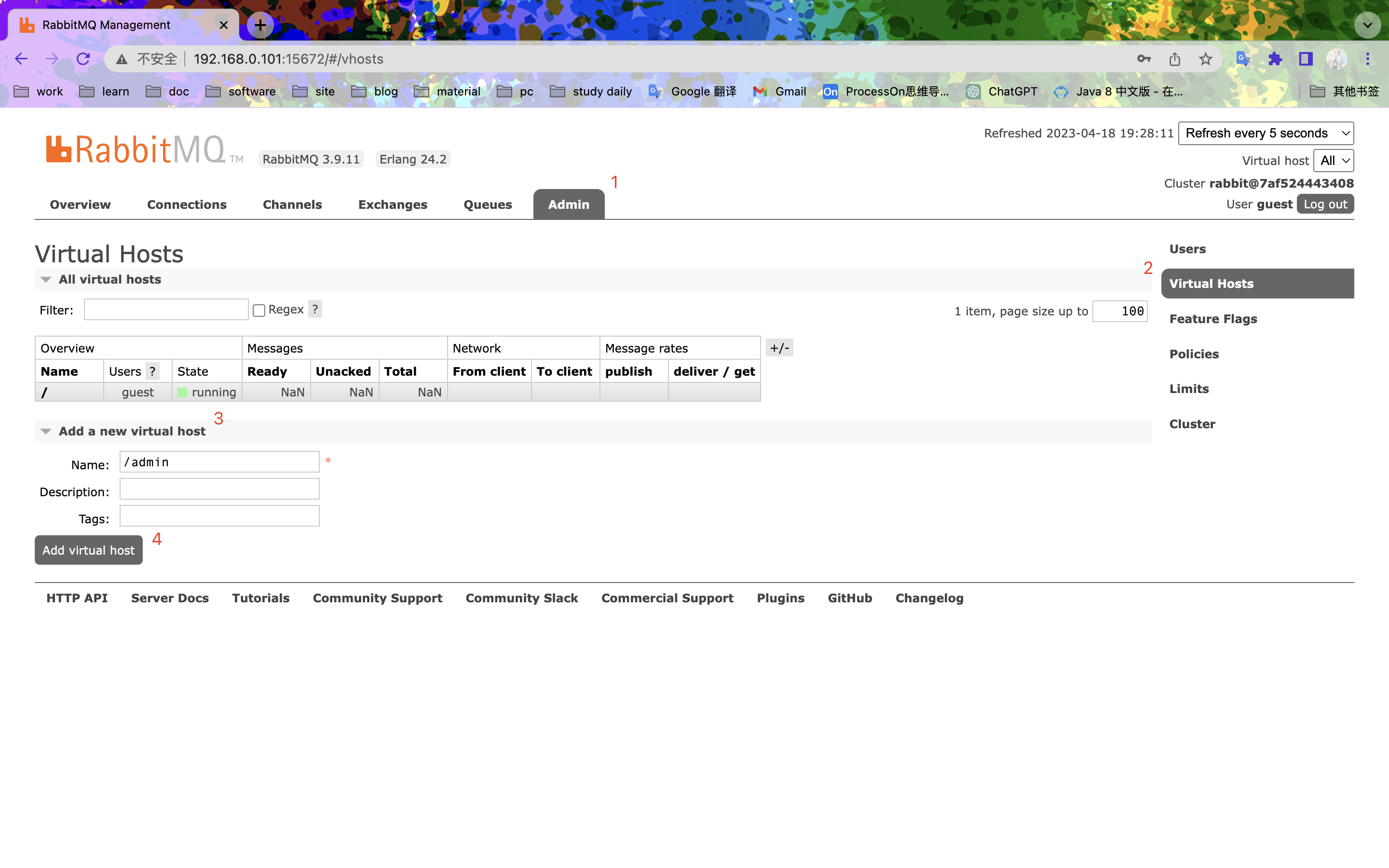
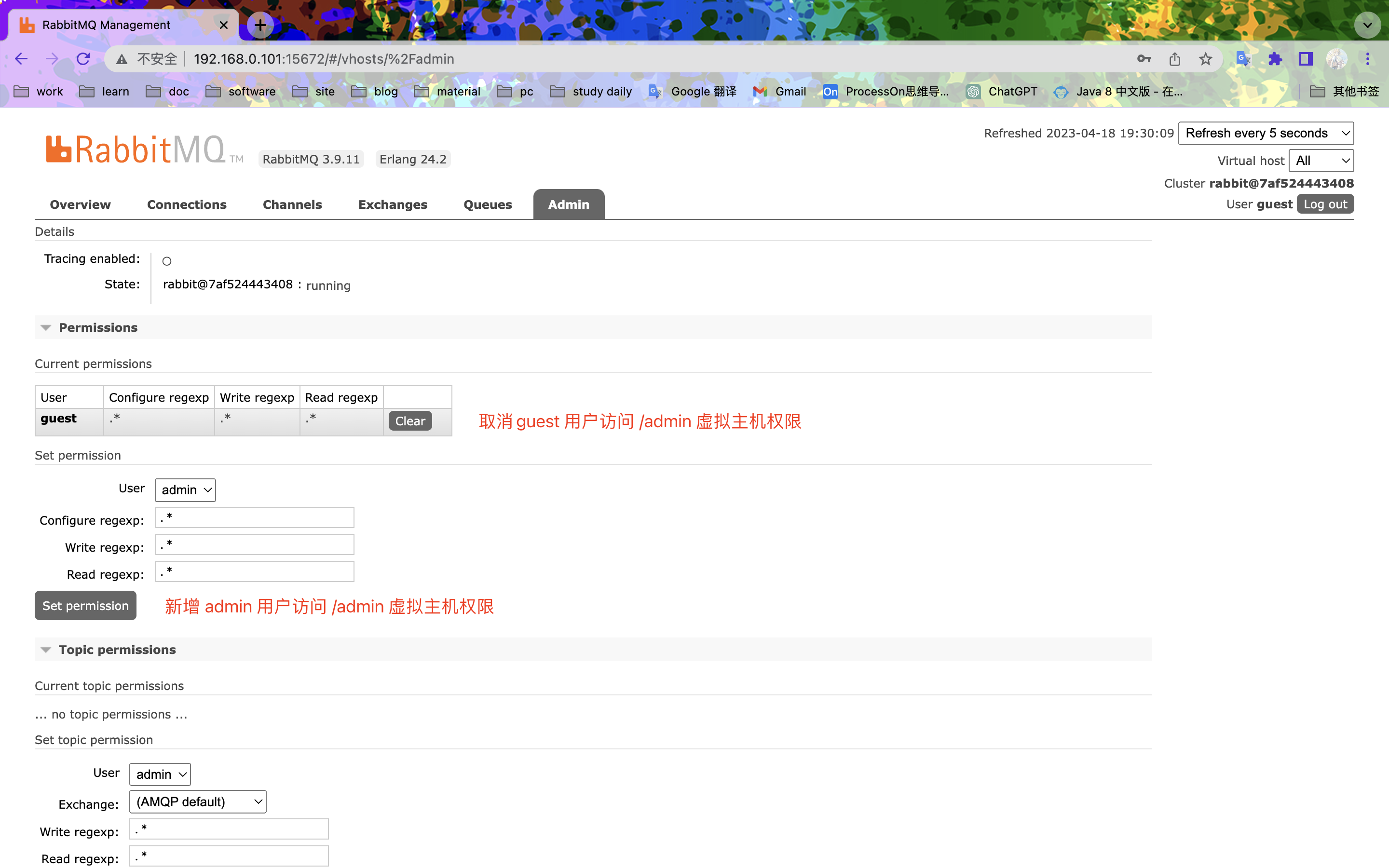
分配权限
控制台页面
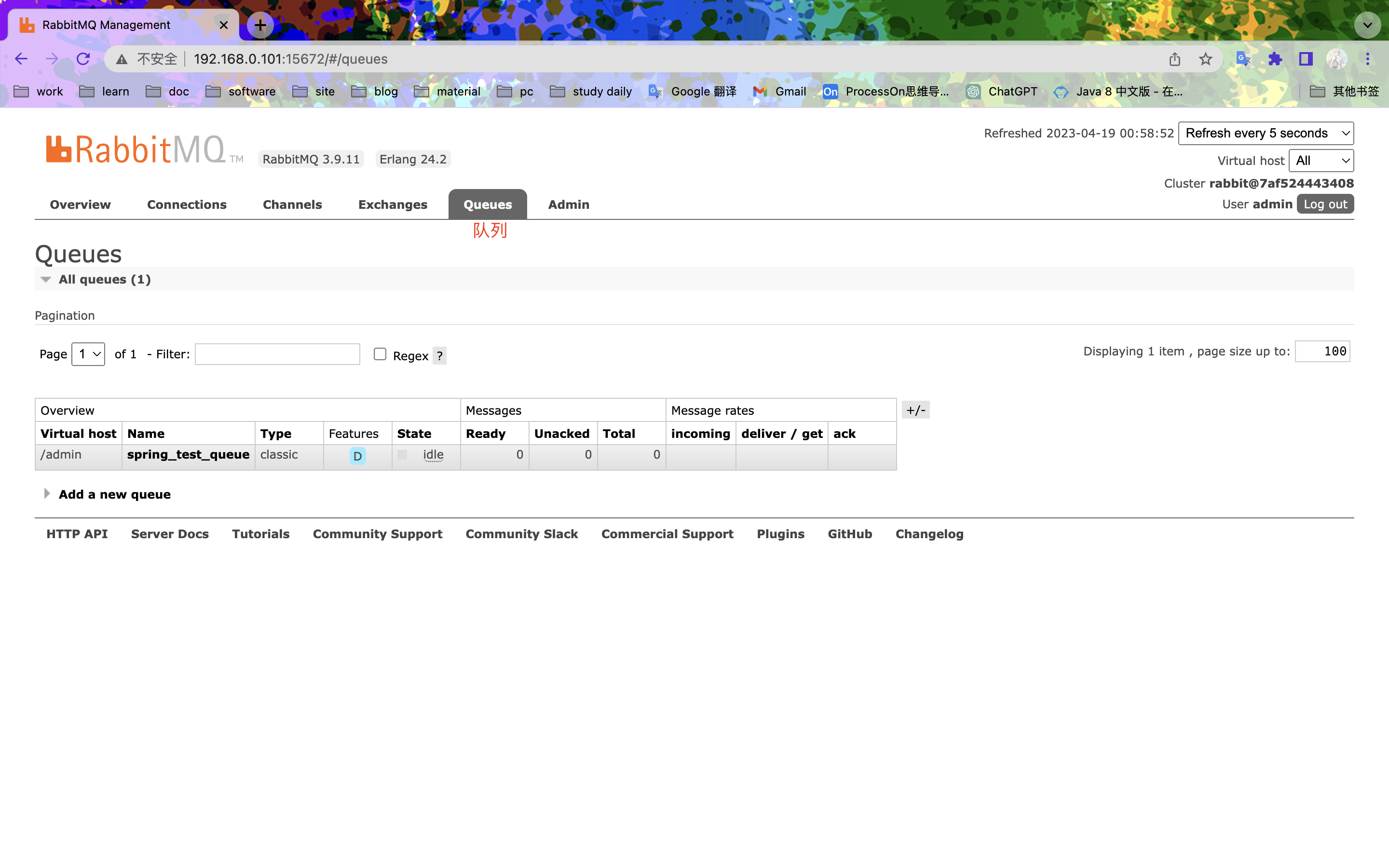
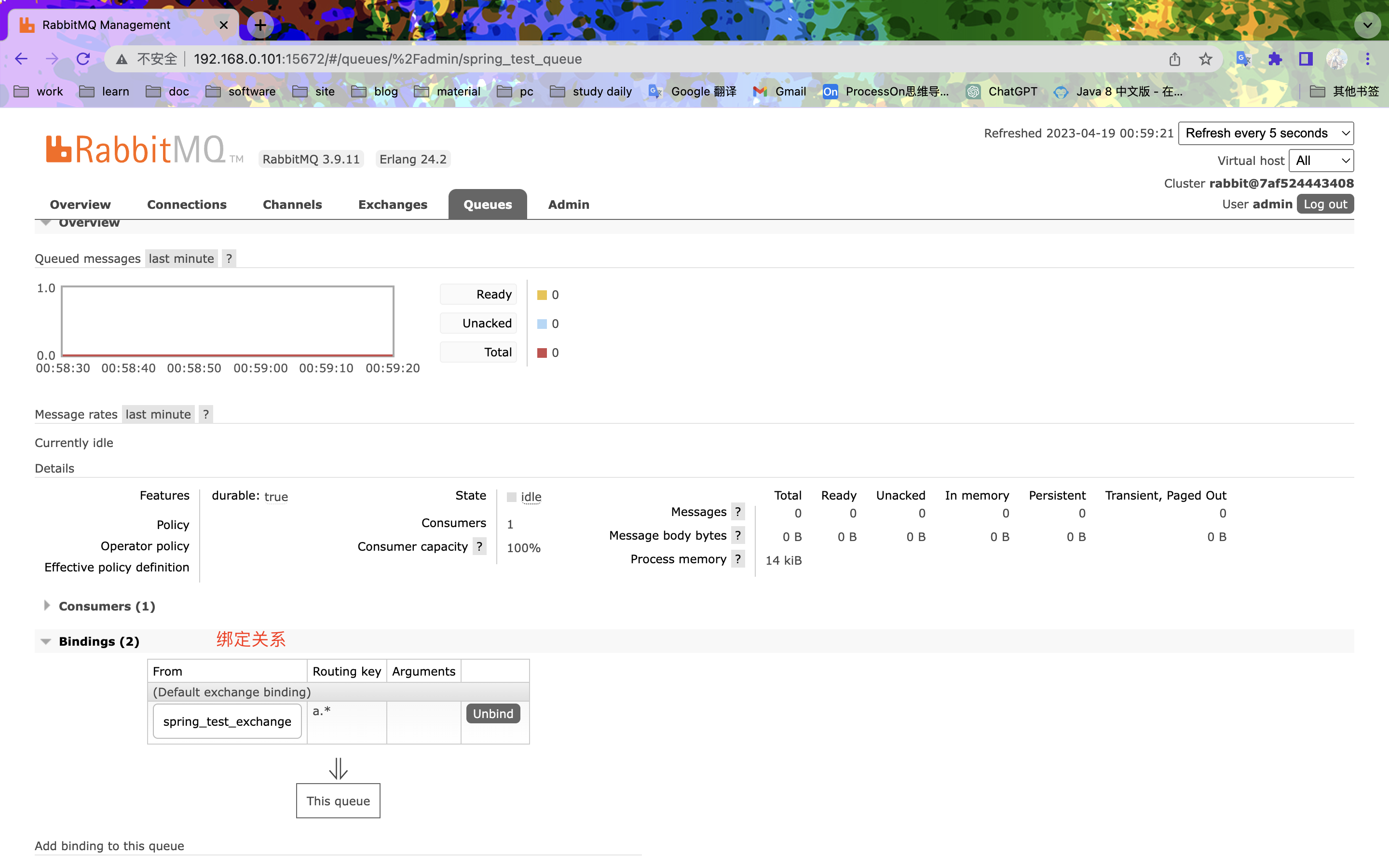
入门案例
消费者
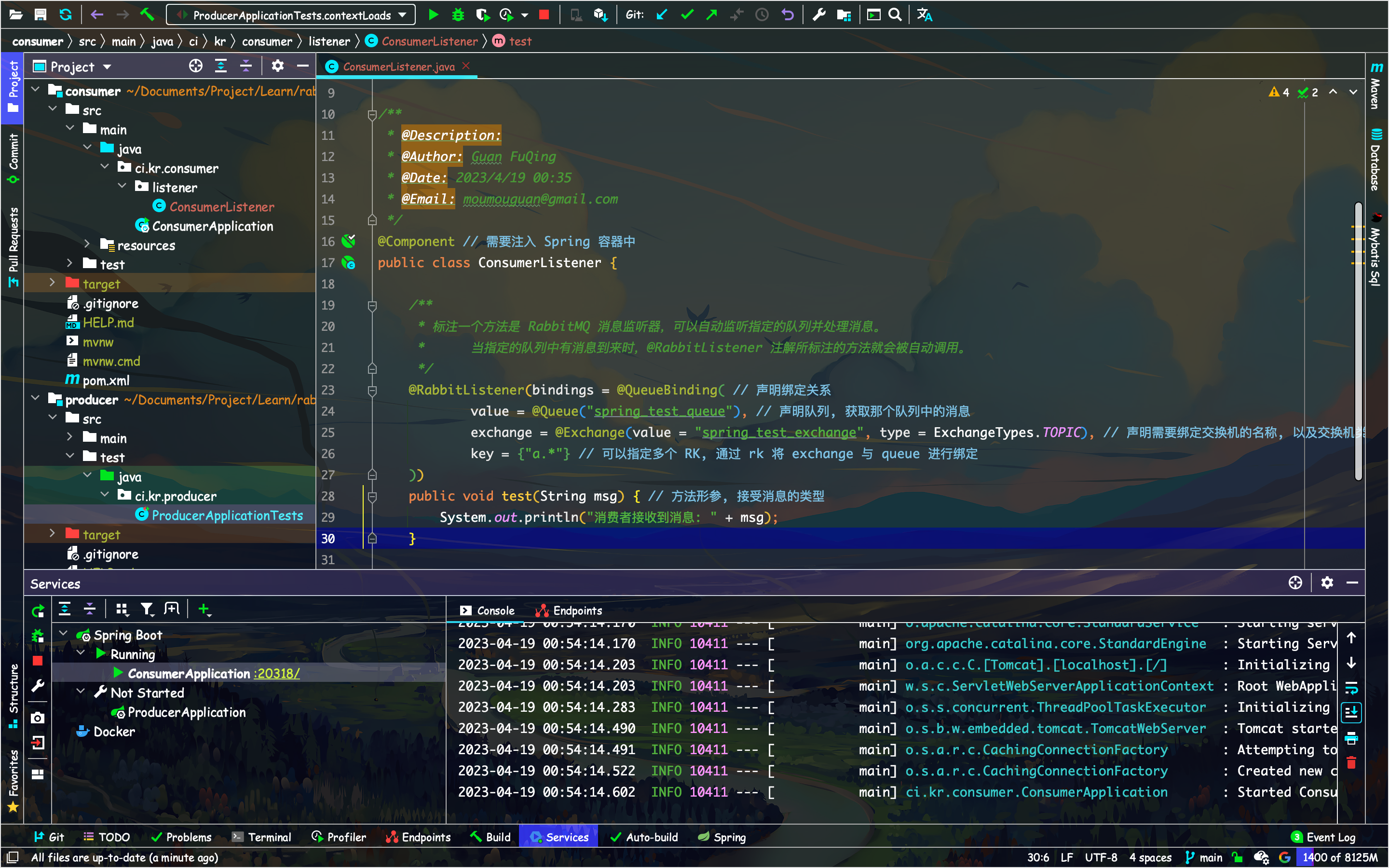
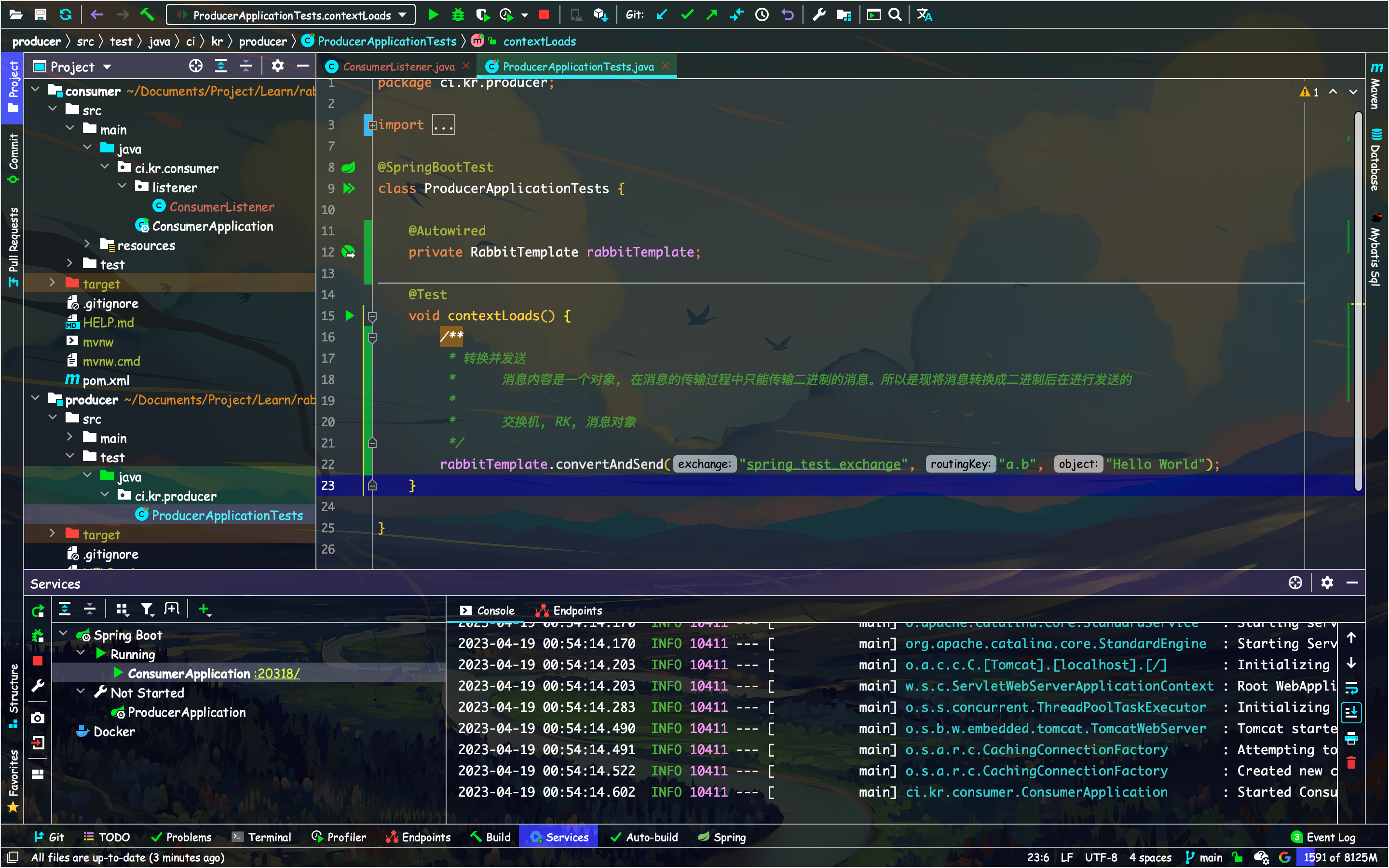
生产者
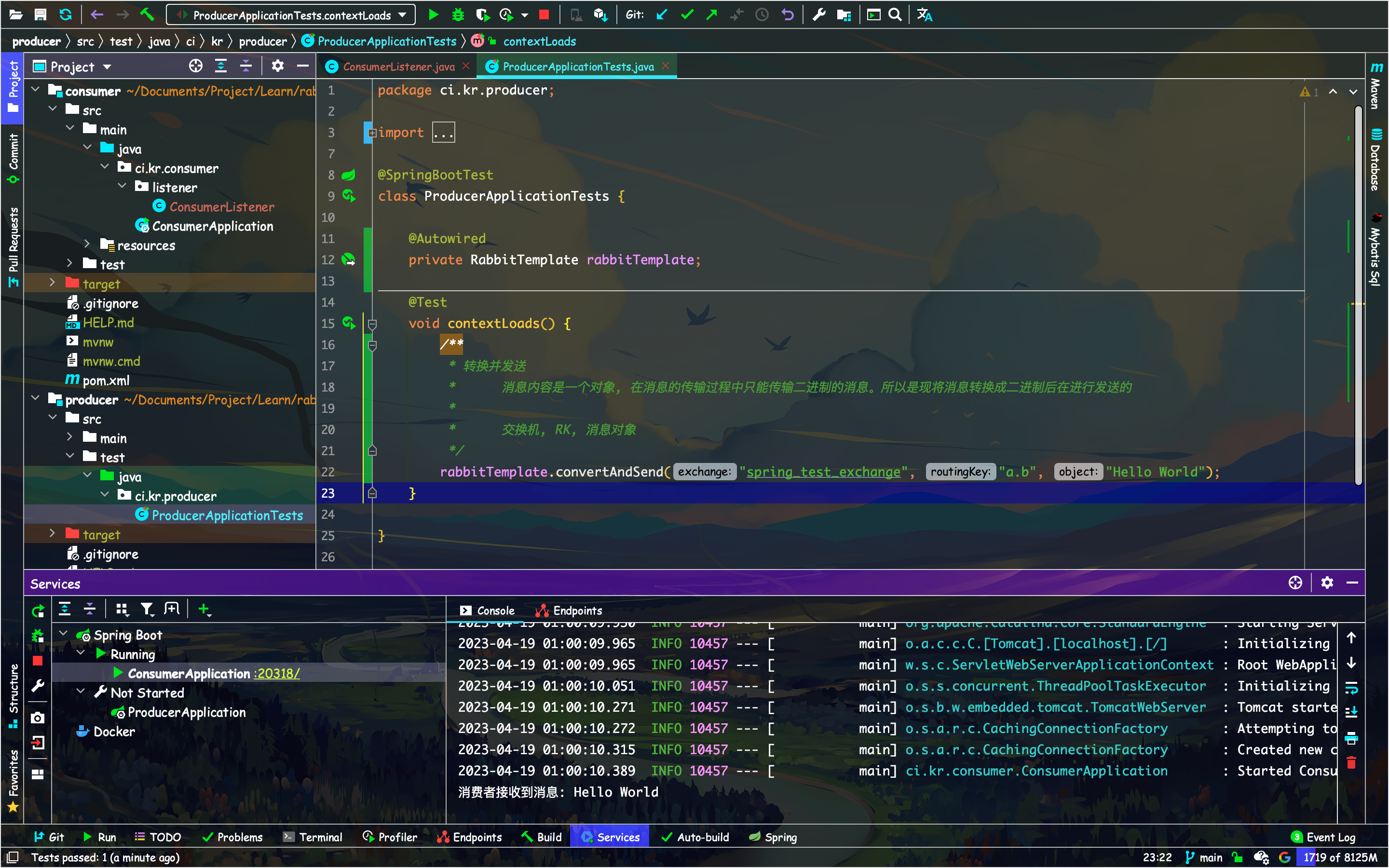
接受到消息
执行流程
如何避免消息堆积(能者多劳以及多线程消费)
1
2
3
4
5
6
7
8
9
10
| listener:
type: simple # 消费者类型: simple-另开线程获取消息, direct-直接使用消费者主线程获取消息
simple:
# prefetch:用于设置从队列中获取消息时的公平分发和能者多劳机制。
# 默认情况下,RabbitMQ 会将消息均分给每个消费者,但每一天机器消费能力有差距。
# 设置 prefetch=1,可以让每个消费者在处理完当前的消息之前不会主动获取新的消息,从而实现能者多劳的效果。
prefetch: 1 # 公平分发 / 能者多劳
# concurrency 属性用于设置消费者的并发数,即同时有多少个消费者实例处理消息。
# 这里设置为 8,表示启动 8 个线程并发处理消息。如果不设置,默认只有一个线程在处理消息。
concurrency: 8 # 多线程消费
|
如何避免消息丢失
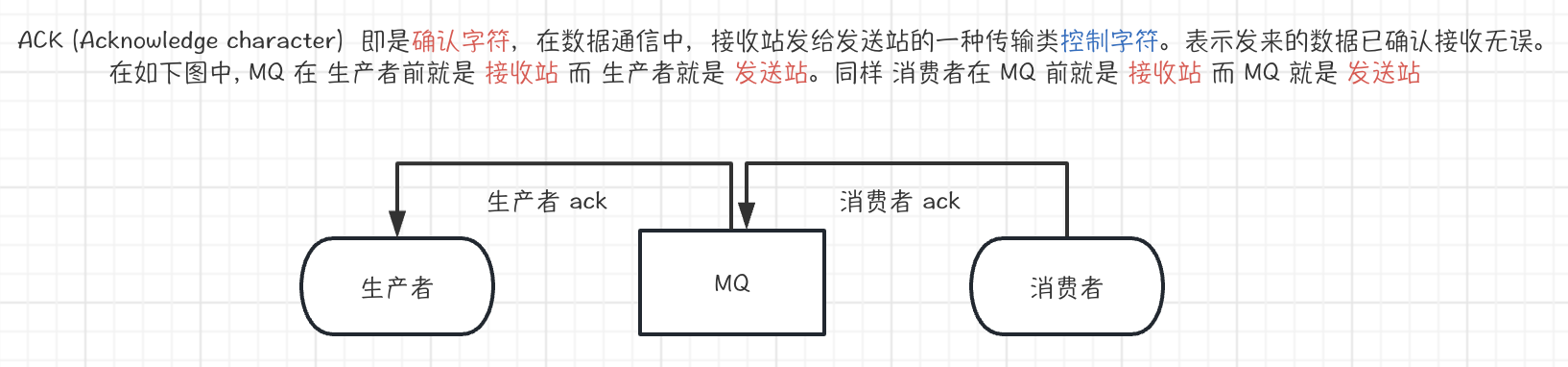
消费者确认
1
2
3
4
5
| # 消费者确认模式
# none: 不确认。只要消费者获取了消息, 消息即被确认。可能会导致消息丢失
# auto: 自动确认。只要消费者在消费过程中没有异常即被确认, 如果出现异常会无限重试。可能会耗费大量 CPU 资源导致服务宕机
# manual: 手动确认。需要手动调用 channel.basicAck 确认消息 / basicNack 不确认消息 / basicReject() 拒绝消息
acknowledge-mode: manual # 手动确认
|
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45
46
47
48
49
50
51
52
53
54
55
56
57
58
| /**
* 标注一个方法是 RabbitMQ 消息监听器,可以自动监听指定的队列并处理消息。
* 当指定的队列中有消息到来时,@RabbitListener 注解所标注的方法就会被自动调用。
*/
@RabbitListener(bindings = @QueueBinding( // 声明绑定关系
value = @Queue("spring_test_queue2"), // 声明队列, 获取那个队列中的消息
exchange = @Exchange(value = "spring_test_exchange2", type = ExchangeTypes.TOPIC), // 声明需要绑定交换机的名称, 以及交换机类型
key = {"a.*"} // 可以指定多个 RK, 通过 rk 将 exchange 与 queue 进行绑定
))
public void test2(String msg, Channel channel, Message message) throws IOException { // 方法形参, 接受消息的类型
try {
System.out.println("消费者获取消息: " + msg);
int i = 1 / 0;
// TODO: 一顿操作.
/**
* channel.basicAck 方法用于向 RabbitMQ 服务器发送确认消息, 告知服务器哪些消息已经被成功处理,并可以将这些消息从队列中删除。
* 游标:message.getMessageProperties().getDeliveryTag() 用于获取消息的标识
* 是否批量确认: 不批量确认,即只确认当前传递标记相关的消息,而不会一次确认多条消息。如果该参数设为 true,则 RabbitMQ 会确认当前传递标记以前的所有消息,可能导致效率降低和消息丢失的风险,因为这些消息可能还没有被完全处理或发送给应用程序。
*/
channel.basicAck(message.getMessageProperties().getDeliveryTag(), false);
} catch (Exception e) {
/**
* 在 RabbitMQ 中,当消费者处理某条消息时,如果由于某些原因导致消费者无法成功处理该消息,那么该消息就会被重新投递给消费者。
* 在消息被重新投递时,消息的 delivery tag 会发生改变,消息的 redelivered 标记会被设置为 true。
*
* 因此,在消费者处理消息时,可以使用 message.getMessageProperties().getRedelivered() 方法来检查当前消息是否为重新投递的消息。
* 如果该消息是重新投递的消息,则可以根据具体的业务场景选择重新处理该消息,或者将其放到死信队列中进行处理等。
*/
if (message.getMessageProperties().getRedelivered()) {
// TODO: 记录日志, 或者保存到数据库表中
/**
* channel.basicReject() 方法用于拒绝消息,即告知 RabbitMQ 服务器该消息无法被消费者处理,需要将消息丢弃或者重新投递到队列中。
* 游标
* 是否重新入队: false 直接删除消息, true 重新投递到队列末尾(如果队列设置了死信交换机并配置了相关参数,第二个参数为 true 时,该消息会被重新投递到绑定的死信交换机并被送往相关的死信队列进行处理。)
*/
channel.basicReject(message.getMessageProperties().getDeliveryTag(), false);
} else {
/**
* channel.basicNack() 方法用于否定消息确认,并将一条或多条消息重新投递到其原始队列。
* 游标
* 是否批量确认
* 是否重新入队: true 表示被拒绝的消息将被重新放置在其原始位置上,而不是放到队列的尾部。
*
* 使用 channel.basicNack() 方法可以灵活地处理消息的确认和重试,例如当消费者在处理某个消息时发生异常或错误时,可以使用该方法将消息重新投递到队列中,以便稍后再次进行处理。如果不使用该方法,则该消息将被标记为已处理,从而可能导致消息丢失或者系统不稳定的情况。
* 由于 channel.basicNack() 方法可以将消息重新放置在其原始位置上,因此当需要多次重试时,可以使用该方法将消息重新投递到头部,以便更快地处理该消息。如果将消息放置在队列的尾部,则可能需要很长时间才能再次处理该消息。
* 需要注意的是,在使用 channel.basicNack() 方法时应该谨慎处理,避免死循环和消息丢失。可以在代码中加入限制条件,例如限制最大重试次数等来确保消息的正确处理。
*/
channel.basicNack(message.getMessageProperties().getDeliveryTag(), false, true);
}
}
}
|
持久化 以及 忽略声明时异常
1
2
3
4
5
6
|
@RabbitListener(bindings = @QueueBinding( // 声明绑定关系
value = @Queue(value = "xxx_queue", durable = "false"), // 声明队列, 获取那个队列中的消息
exchange = @Exchange(value = "xxx_exchange", durable = "false", type = ExchangeTypes.TOPIC), // 声明需要绑定交换机的名称, 以及交换机类型
key = {"*.*"} // 可以指定多个 RK, 通过 rk 将 exchange 与 queue 进行绑定
))
|
1
2
3
4
5
6
|
@RabbitListener(bindings = @QueueBinding( // 声明绑定关系
value = @Queue(value = "xxx_queue", ignoreDeclarationExceptions = "true"), // 声明队列, 获取那个队列中的消息
exchange = @Exchange(value = "xxx_exchange", ignoreDeclarationExceptions = "true", type = ExchangeTypes.TOPIC), // 声明需要绑定交换机的名称, 以及交换机类型
key = {"*.*"} // 可以指定多个 RK, 通过 rk 将 exchange 与 queue 进行绑定
))
|
生产者确认
1
2
3
4
5
6
7
|
publisher-confirm-type: correlated
publisher-returns: true
|
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
|
@PostConstruct
public void init() {
rabbitTemplate.setConfirmCallback((correlationData, ack, cause) -> {
if (ack) {
log.info("消息已经到达交换机。");
} else {
log.error("消息没有到达交换机。原因: {}" + cause);
}
});
rabbitTemplate.setReturnCallback((message, replyCode, replyText, exchange, routingKey) -> {
log.error(
"消息没有到达队列: 交换机: {}, 路由键: {}, 消息内容: {}, 状态码: {}, 状态文本: {}" +
exchange, routingKey, new String(message.getBody()), replyCode, replyText
);
});
}
|
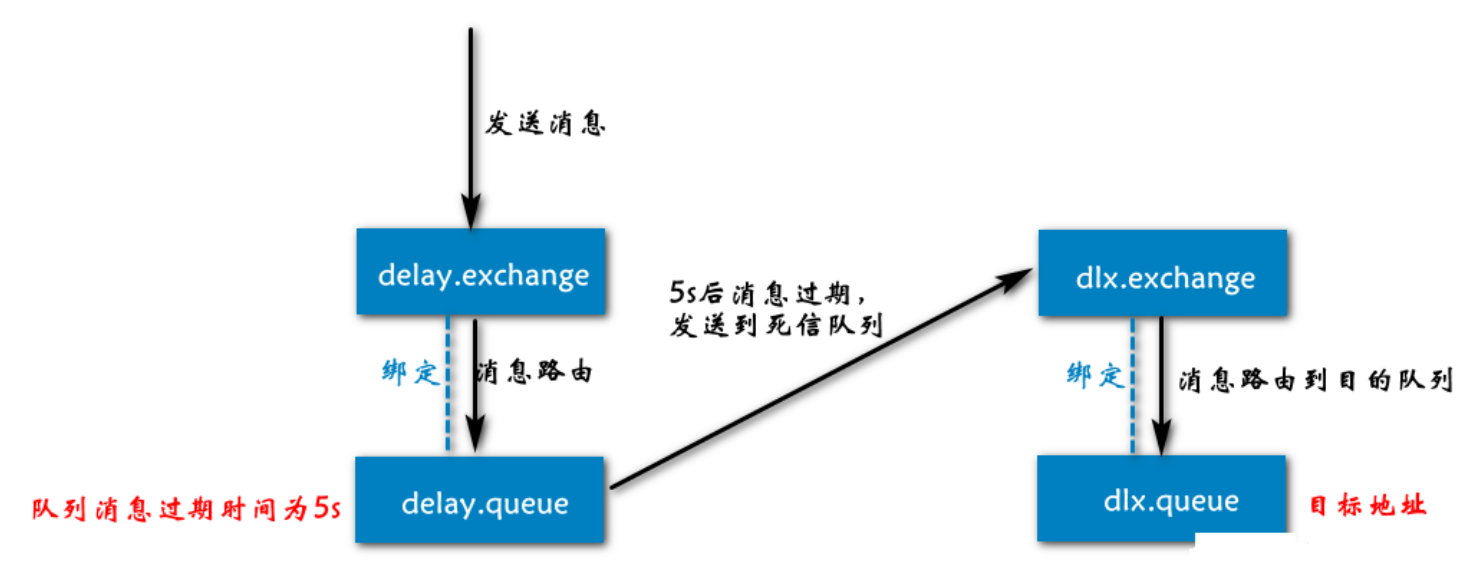
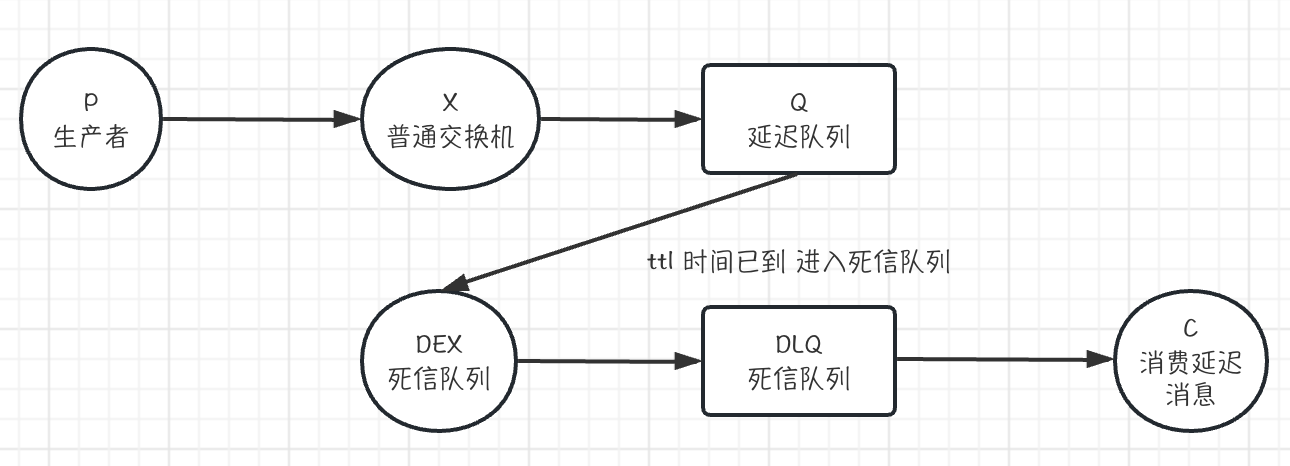
死信队列
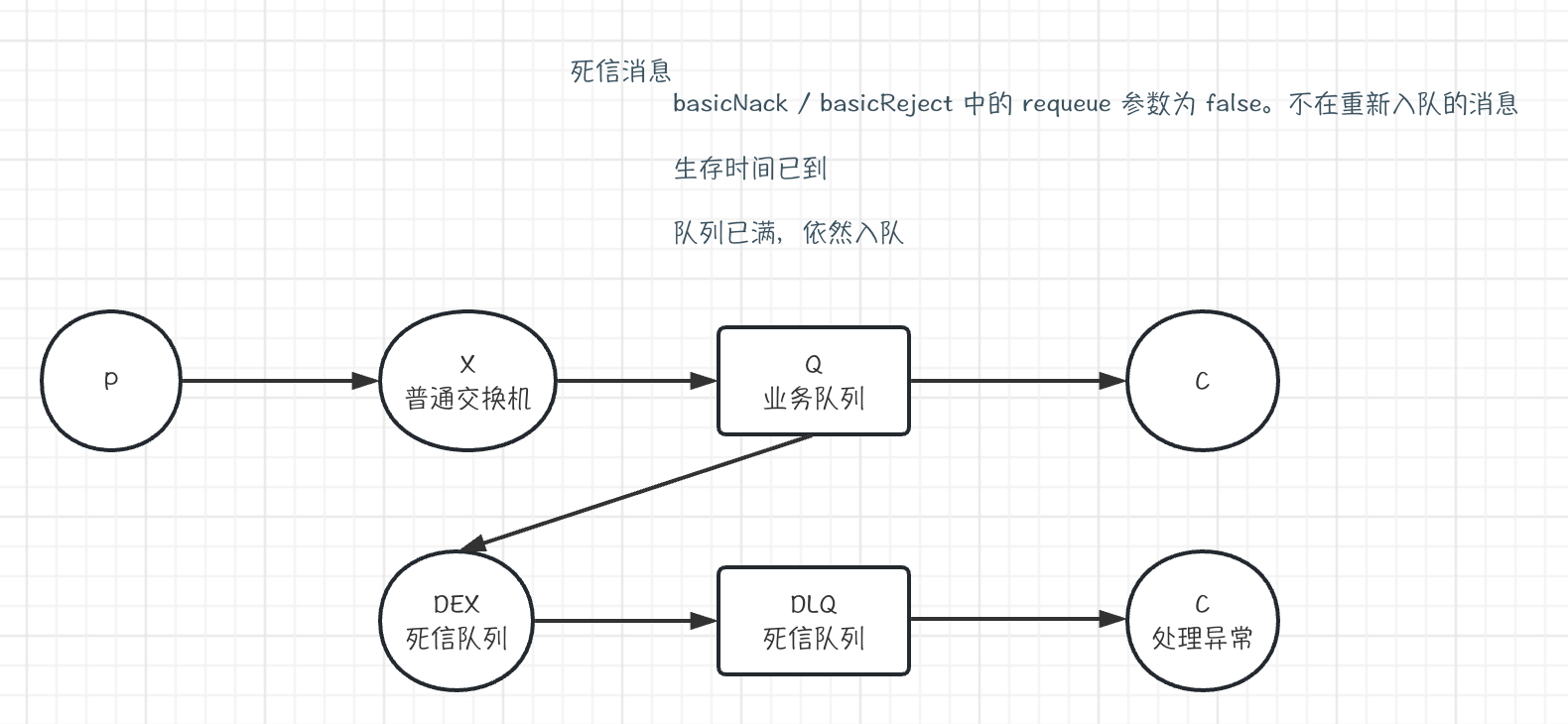
延迟队列